About this site
Welcome! This is a site where I share my take on subjects that interest me and ideas that excite me.
My hope is to reach as many of my friends and like-minded people around the world, engage them in stimulating conversations, and to learn and improve from our shared experiences.
While I have worn many hats in my life, I am a programmer by trade. By that I mean, someone who uses computers and programming tools to solve problems. While I will not try to hide this bend in my explorations in this site, all avenues will be pursued to make the ideas reach as far and wide as possible. I sincerely hope that I am able to engage you irrespective of your professional background or technical depth.
I have kept this site to be minimal and functional, serving the purpose of sharing information and code with as little distractions as possible, while discussing topics that are important to both technical and non-technical audiences. It is organized like a book with chapters. These are documents edited in Visual Studio Code and published directly from a GitHub repository. Using the tools of the trade, so to say.
This site respects your individuality and right to privacy. It doesn't serve you cookies, Neither will it pry or spy. It will not track you, trace you, Categorize you, profile you or target you.
You can always share your feedbacks and comments by mail.

Copyright 2023 Weavers @ Eternal Loom. All rights reserved.
Systems Thinking
No, this is not another article about ChatGPT and how it is going to takeover everyone's job. Don't get me wrong! I am as excited about the revolutionary potential of machine learning (ML) technology as the next person. But here and now, we are just going to think in terms of good old systems.
Thinking in Systems by Donella H. Meadows is an excellent introduction to systems thinking. It roughly defines a system to be a set of interconnected elements with a purpose where the sum is more than its parts. The central thesis of the book is that a system's behavior is intrinsic to the system itself and to produce better results from a system, we need to understand the relationship between the structure and behavior of that system.
I will not indulge in the details of systems theory here, but rather focus only on aspects relevant to building digital systems, specifically, software systems. With digitization of every worthwhile human pursuit, we are all part of a global machinery that turns physical reality into mindless stream of bits, willingly or not. A never ending quest for efficiency and speed that challenges us to conquer ever growing complexity of digital systems and infrastructure. A journey that forces us to confront the limits of our own tools and techniques far too often, and to seek new ways to build better systems.
A byte out of systems
How do we go about building programs that mimic physical systems?
We develop models of physical systems. As pointed out in Structure and Interpretation of Computer Programs1, "One powerful design strategy, which is particularly appropriate to the construction of programs for modeling physical systems, is to base the structure of our programs on the structure of the system being modeled."
This turned out to be a very effective strategy as evidenced by the huge popularity enjoyed by Object Oriented Design (OOD) and Object Oriented Programming (OOP) in the industry. While there are genuine criticisms that can be leveled against OO approaches, they are a natural fit when modeling systems in many practical domains.
The role and importance of domain models in software development can't be overstated. They are the foundation of any software system. From eliciting the structure and behaviors of systems, establishing the architectural blueprints, verification and validation of working software to deploying and operating them on distributed, virtual infrastructures of today, domain models play a critical role. They may sit majestically at the center of our software development arena or hide in the shadows of its dark alleyways. They lurk behind the software systems of all sizes and shapes, whether we formally acknowledge them or not.
Domain Driven Design (DDD), an approach to software development that centers the development on programming a domain model that has a rich understanding of the processes and rules of a domain (Martin Fowler, 2020), based on 2003 book by Eric Evans, has been widely adopted and applied in the industry. The adoption of a Ubiquitous Language (UL), a common rigorous language of communication between developers, domain experts and domain users is a core concept of DDD. Its bias towards developing models in software and its evolutionary approach to model development has made it attractive to the development community, especially to Extreme Programming (XP) and Agile practitioners.
The focus of DDD is on building better domain models whereas the related approaches of Model-Driven Engineering (MDE) and Model-Driven Architecture (MDA) are more concerned with translating the models into code. But taken together, they provide the essential tools for building better software systems faster, a way to transform strings of conscious reality into streams of flashing bits.
The great divide
As Albert Einstein2 stated, "... the supreme goal of all theory is to make the irreducible basic elements as simple and as few as possible without having to surrender the adequate representation of a single datum of experience." And there in lies the relentless quest for foundational modeling elements that connect the objective reality of a domain user to the abstract constructs in some programming language.
How do I know there is a gap? I asked ChatGPT, seriously.
Me: Is there a gap between domain models and programming models?
ChatGPT: Yes, there is often a gap between domain models and programming models. Domain models represent the concepts and relationships within a specific field or domain, while programming models are concerned with representing these concepts in code. Bridging this gap can be challenging as the concepts in the domain model may not have a straightforward mapping to code, and vice versa. It requires a good understanding of both the domain and the programming language to effectively translate between the two.
The irrefutable proof of truthiness one can hope for in 2023!
This kind of gap is more fundamental and deep, pervading all fields of study. Philip Anderson, a Nobel Laureate in Physics, in his 1972 article eloquently argued that "more is different" and "ability to reduce everything to simple fundamental laws does not imply the ability to start from those laws and reconstruct the universe". When dealing with the dual difficulties of scale and complexity, he cautions about the emergence of new properties at each level of complexity needing different abstractions (fundamental laws) to explain new behaviors.
As we tackle complex domains, attempting to model emergent behaviors at each level of complexity, shoehorning them into the existing programming models, most of them originally designed to deal with memory representations and machine code generation, leads to cognitive dissonance and compromised models. Wrong models lead to wrong systems, period! The saying, "You can't fix stupid" is no more truer in any other context.
Not all programming languages are the same. Each one was designed with a different purpose in mind. Overtime, they evolve, supporting multiple paradigms and the developer communities build better abstraction layers on top of them to address the aforementioned gap. From a systems perspective, what is important is how we tame domain complexity and handle emergent behaviors.
Time honored way to solve complex problems is to decompose them into smaller, simpler ones and solve them independently. The way to build complex systems, would be to compose them from simpler ones. A fact we might be willing to accept as self evident. But as Anderson pointed out, "a reductionist hypothesis does not imply a constructionist one". Since modularity, coupling, cohesion and information hiding were part of software engineering vocabulary for ages and nearly universal practice of modular organization of code, we naively assume that we are composing software systems, when in fact, we merely decompose them. We will explore this subtle, but crucial difference in more detail in another chapter. But for now, I will simply state that the composition models across programming paradigms require a different set of abstractions.
All programming languages provide means to model structure in terms of values (entities, value objects, classes, etc.) and relations (inheritance, aggregation etc.), typically encoded in a type system. They also support modeling the interactions using interface definitions (functions, protocols, interfaces, traits, instance methods, etc.). The behaviors emerge from dynamic states of the system that change as a consequence of computations initiated through interfaces. We can really flex the powers of type systems and modern compilers to go a long way to model and validate systems. If you are curious, there is delightful series on Designing with types by Scott Wlaschin, that might be of interest to you. I will continue with my deliberations on dynamic states and encapsulating emergent behaviors here.
Data modeling has a long and storied history. It is a rich and well established field supported by a thriving database community. The databases and their schemas have been powering most of the systems out there. When we refer to model in an application context (Model, View, Controller (MVC) pattern as example), we are often referring to the data, usually stored in some database. Yet there seems to be a divide between the modeling aspects of data pertaining to data layer and computation (or application logic) layer. One focuses more on data at rest while the other is concerned about the data in motion (transition). But both have to deal with the dynamics of the system (the changing states) or emergent behaviors.
Data community does this by shoving more status fields into their tables and documents while the application community deals with them by writing a truck load of code in the name of controllers and logical blocks. The very essence of our system lives in the wild wild west of broiler plate code that is built to tie these disparate worlds together.
Can we have a unified model of a domain that crosses the boundaries of client, server, middleware, databases and other artificial boundaries we have created to organize our teams, software artifacts and infrastructure? Can we do this without all the ceremony and fanfare?
In a much simpler past, many of us could standardize on a single programming language and move on. Not any more. Between our web and mobile applications, multiple public API's and language specific SDK's that we provide to our customers for accelerated adoption, we end up shoehorning our domain models many times over. It is not just the domain complexity we are up against, but the complexities presented by the realities of global, distributed, hybrid, virtual, polyglot environments of today. Our domain models have to transcend the very confines of programming languages whose programming model we want them to be part of!
If you have lead your professional life oblivious to the above challenges, don't feel left out. In any growing business, you will soon be forced to confront them. Sleep well tonight!
It is not just about programmer productivity. We fill the gap between the
domain user and programmer with different roles - domain experts,
domain consultants, business managers,business analysts, data analysts,
product managers. We equip them with even more automation tools each
churning out their own digital artifacts. Meanwhile, the real developer
spends all her time writing broiler plate code to bring all of them
together. The official estimates of broiler plate code ranges from
20 to 30%, but in sufficiently complex projects, they easily exceed 50%.
A domain model, first and foremost, is a communication tool. It is where we collect, organize, analyze and refine the tiny, shiny granules of domain wisdom. Domain models help build a common understanding and align goals among the stakeholders. They inform and guide the design, implementation and validation of the digital systems we build. The simplicity and expressiveness needed for effective stakeholder communication often stands at odds with the implementation details that creep into the programming models. For all the allegiance we pledge to working software over comprehensive documentation, we end up doing both, by different people.
As we digitize the domain knowledge, we are at the risk of burying more and more of our organizational knowledge in code. In any modernization project in any organization with some history, there is always a spreadsheet or a piece of software that nobody wants to touch. Everyone knows it is important, but no one knows how it works. Marvels of modern architecture built around leaking legacy sewage! The modern systems we build today are the dark abyss of organization knowhow of tomorrow. Just think about the amount of knowledge that is buried in data models, database schemas, spreadsheets and code repositories in our organizations.
In biology, we study changes to organisms (biological systems) from a developmental and evolutionary perspectives. We have been looking systems and their models from a developmental perspective, exploring their changes over a single lifespan. All systems evolve over generations. Building models resilient to changes under evolutionary pressures of systems they model is key to their success. Just as we avoid under or over-fitting our models to data in our machine learning (ML) systems, we have to be careful about how well we fit our models to the requirements of the systems. Build for change is a mantra that we profess with passion, but pursue with extreme prejudice. Just as we concluded that the emerging behaviors need different kinds of abstractions, we have to explore abstractions that enable us to deal with the evolution of systems as well.
Crossing the chasm
It is fair at this point to ask, "What do we want, really?".
- We want to apply systems lens to building software.3
- We want powerful domain models that can capture the structure and emergent behaviors of complex systems.
- The systems and their models should be composable.
- The domain models should be simple, expressive and enable effective communication between stakeholders, especially bridging the chasm between the domain user and the programmer worlds.
- We want better abstractions built on our programming models to reduce the degrees of separation between the specifications and working software.
- Our models should transcend the artificial boundaries of programming languages, implementation details, software and organization structures, and deployment environments.
- Models capture organizational learning and knowledge. They should not be buried in code.
- We want to build models that are resilient to change.
We will explore how we can achieve these goals in the upcoming chapters. A journey that will take us through models, programming languages, type systems, knowledge representation, state machines and even polynomials!
Why, I wonder?
We have been building software systems for ages now. Do we really need to bother?
I would like to ask a counter question. Do we really need to spend millions of dollars to build a new chat application? Can't we just Google things?
Apparently, even Google does not think so.
Keeping with my stated intention of focusing the discussions here on technology and solutions, I will not attempt an elaborate business case based on lost productivity, time to value or any number of other flavor metrics of the day. If this is an impediment to your appreciation of the subject matter, please do reach out to me.
We are a species that progressed by building better tools and systems. It is our survivalist instinct. It is what makes us who we are.
Prof. Robert Sapolsky, in his lecture Uniqueness of Humans, said it best. "The more clearly, absolutely, utterly, irrevocably, unchangeably clear it is that it is impossible for you to make a difference and make the world better, the more you must."
So, we must!
Request for feedback
I like to hear from you.
Please share your comments, questions, and suggestions for improvement with me!
This book is a classic and a must read for any self-respecting programmer.
It is an unwritten rule that one can't discuss models without an obligatory quote from Albert Einstein.
Systems analysis and design methodologies have been used in software development for a long time. I hope the practitioners of these methodologies can appreciate the differences in perspectives here.
Copyright 2023 Weavers @ Eternal Loom. All rights reserved.
None of Your Business
Freeman Dyson, recounted a conversation with Enrico Fermi in 1953 when he was asked how many arbitrary parameters did he use for his calculations? When he answered "four", Fermi famously replied, "I remember my friend Johnny von Neumann used to say, with four parameters I can fit an elephant, and with five I can make him wiggle his trunk.”1
Those parsimonious old geezers and their occam's razor!
GPT-3 has 175 billion parameters. No wonder it can fit the world and all the bad jokes in it.
When it comes to building software and modeling business domains, we hardly think about the number of parameters we are using. We never hear about the tensions boiling over the number of parameters used in our models between the business development and engineering. Probably a good thing if you are an engineer working at Twitter.
A notable exception here is the Machine Learning (ML) community. With the success of Large Language Models (LLM) like GPT-3, the number of parameters has become a fascination and a fad. We are already way past a trillion parameter mark and there is always rumours of an even bigger one in the works. Apparently, as far as the future of AI is concerned, the size matters!
Even if you perceive these advances with fearful trepidations about the rise of sentient machines or with a sense of disappointment that the human intelligence might be reduced to mere statistical regularities or with shear skepticism about the technology hype cycle, you can't ignore the influence these technology advances are having in how we build our digital systems. It is important to explore how they play into the domain and programming model challenges that I alluded to in my previous article.
First and foremost, in a world where systems can learn themselves from trillions of tokens on the web, encoding the collective human knowledge into weights and biases in hidden layers of some artificial neural entanglements buried deep beneath a friendly prompt, why do we need domain models at all?
The weights and biases that defines us
Richard Sutton2 points out the bitter lesson from 70 years of AI research that the methods relying on scalable computation, such as search and learning, always outperform the methods attempting to hand engineer the human knowledge of the domain. In his words, "We have to learn the bitter lesson that building in how we think we think does not work in the long run."
In other words, letting go to grow up in the real world applies equally well to your kids and systems.
To understand what it all means, we need to dig a little bit deeper into the world of the modern ML systems. I will try to keep this at a high level, but shall provide sufficient pointers to details for those who are interested. Another note of caution, this is a field that is rapidly evolving where innovations are happening at a breakneck pace and our understanding of how things work is shifting at an equal pace. It is almost impossible to be current on all the advancements, let alone predict their impact on the future of systems engineering.
It is also a very diverse field. Our discussion here is not intended to be a survey or tutorial of the field. Our approach here will be to understand the implications to systems engineering by exploring some of the most prominent trends in this field, specifically from the vantage of the Large Language Models (LLM).
In the traditional world I discussed in the previous article, when we set out to build a digital system, we construct our model that captures the essence of the actual system we are trying to build. We model the entities, their relationships, states and behaviors. We then immortalize this model in some programming language. Here we are in charge of defining everything. Even though there are differences in the way a domain model is captured by a domain expert and a software engineer, the model is still a human construct that has close correlations in both worlds. From a representation perspective, they use the representational systems that we have developed for ourselves for the very same purpose.
For e.g., a domain specification might say something like, "A user has a name, email address, and a role. The role can either be regular or admin." A pretty dry domain description that we are all used to. This can be translated into a programming language as follows:
#![allow(unused)] fn main() { /// User with name, email, and role struct User { name: String, email: String, role: Role, } /// Role definitions for a user enum Role { Regular, Admin, } }
The above code is written in Rust, a modern systems programming language. Even if you don't know Rust, you can probably recognize the representation of the domain knowledge captured by the code and its relation to its corresponding statement form.
We can create a user, print the information about that user and make sure that it looks exactly like what we expected. You can run all the Rust code right here by clicking on the "Run" button [▶︎] inside the code block.3
/// User with name, email, and role #[derive(Debug)] struct User { name: String, email: String, role: Role, } /// Role definitions for a user #[derive(Debug)] enum Role { Regular, Admin, } fn main() { // Create a user "John Doe" let user = User { name: "John Doe".to_string(), email: "john@doe.com".to_string(), role: Role::Regular, }; // Print the user information println!("User: {:?}", user); }
Here is the same code in Python:
@dataclass
class User:
name: str
email: str
role: "Role"
class Role(Enum):
REGULAR = 1
ADMIN = 2
user: User = User("John Doe", "john@doe.com", Role.REGULAR)
print(user)
You can't run Python code directly here, but you can run them at Google Colab
by clicking this badge
![]() .
.
While specific details are irrelevant to our current discussion, one point to note is that the model of the world reflects our way of understanding and representing it and the code follows closely. After all, that is why we invented higher level programming languages in the first place.
The most important point here is that the model contains information that we have explicitly captured through our understanding of the world. We demand nothing more or expect nothing less from the digital system that uses this model. If we want the Users to have an address for example, we have to explicitly add it to the model.
Similarly, the structural relationships are hardwired into the model. A user has only one role because we specified and coded it that way. We have handcrafted the features to be used in the model. This is what Rich Sutton alluding to when he talks about humans building knowledge into agents.
Essentially, the system has no learned representations or emergent behaviors.
This is quite different in the land of the LLMs. Let us try to understand what happens in the world of LLMs4.
Token like you mean it
Whether you are using an existing LLM or building a new one, the first step is to find a way to tokenize your inputs. Tokenization is the process of breaking down the input into smaller pieces, encoding them as numbers, and creating a dictionary of these tokens. It is like learning to breakdown sentences into words in a new language and then creating a numeric index for each word. There are many ways to do this and most of these tools are readily available for use5.
If we feed our domain specification to GPT-3 tokenizer, we will get the following sequence of 22 tokens:
Input Text:
A user has a name, email address, and a role.
The role can either be regular or admin.
Output Tokens:
[32, 2836, 468, 257, 1438, 11, 3053, 2209, 11, 290, 257,
2597, 13, 383, 2597, 460, 2035, 307, 3218, 393, 13169, 13]
* I have split the text and tokens into lines for easy reading. They are just a sequence of characters and a sequence of numbers respectively.
Different tokenizers give different tokens. I have included some sample code
in the companion notebook for you to see these tokenizers in action
![]() .
Depending on the volume and type of data the tokenizers were
trained on, they will have a different vocabulary size. The GPT tokenizer
has a vocabulary size of 50,257 and BERT (another popular open source
LLM model from Google) has a vocabulary size of 30,522. The vocabulary
size influences quality and performance of learning as well as the size of
token sequence generated for a given input. Large vocabulary size increases
memory and time complexity of training while reducing the number of tokens
in the sequence.
.
Depending on the volume and type of data the tokenizers were
trained on, they will have a different vocabulary size. The GPT tokenizer
has a vocabulary size of 50,257 and BERT (another popular open source
LLM model from Google) has a vocabulary size of 30,522. The vocabulary
size influences quality and performance of learning as well as the size of
token sequence generated for a given input. Large vocabulary size increases
memory and time complexity of training while reducing the number of tokens
in the sequence.
When we are dealing with modalities other than text, such as images, audio, or video, we will have other schemes to split the input into encoded sequences6.
As you can see, the tokens are important because we need them to get anything in and out of LLMs and any systems that rely on them. Different LLMs use different tokenizers and each tokenizer generates different token sequences and has different vocabulary size7. There are cases when you may want to modify existing tokenizers or even create new ones altogether. There is so much more to tokens than what my short description and code snippets convey.
In case any of you are wondering if this is any of your business to know, let me give you one more perspective.
Since companies like OpenAI charge by the number of tokens, it is important for us to have a basic understanding of tokens. At the time of launch, the ChatGPT API charges $0.002 per 1000 tokens. As per their rule of thumb, 1000 tokens translates to approximately 750 words in common English. Brings a new perspective to the phrase "use your words carefully", doesn't it?
To make the long story short, inputs to the LLMs are long sequences of tokens. These tokens are precious because they are not mere tokens of information exchange, but real dollars and cents. Soon enough, they are going to show up in your cost of services and OpEx, center of your buy vs. build decisions, and target of your operational efficiency initiatives.
It will soon be everybody's business!
Tell me I forget, Embed me I learn
We have created tokens and given them identities. But they lack any meaning in their lives. They are just like us. A social security number or student ID card gives us identity. But we find meaning in our lives through our interactions with the people and places around us. It is our shared experiences that enrich us. We just need to let our tokens do the same by creating a space where they can find each other, learn from one another, build their character and in the process discover their own meaning and place in the world.
In the machine learning world, this process is called embedding. And the space where they are embedded is simply known as the embedding space. Obviously, there was no marketing department involved when they were naming these things!
Embeddings are numerical representations of concepts converted to number sequences. That sounds awfully similar to the tokens we just talked about, except that they are much more.
When we talk about people, we are all used to phrases like "the depth of their character", "the breadth of their knowledge", or "being plain or a square". We are alluding to some dimensionality using some abstract coordinate system in these metaphors. Or more concretely when we describe a point in space with its x, y, and z coordinates. What is good for the goose might work for the gander. What if we represented the token's meanings using values in a number of dimensions? Since we are not sure what these tokens might learn and how many dimensions are actually needed to represent their learning, we just choose an arbitrarily large number of dimensions that we can afford (computationally). In mathematical terms, it is a vector that you might remember from your linear algebra or physics class. With some proper training, we can hope that each of these tokens will learn their coordinates in this high dimensional space. And that is, in essence, the art and science of embedding, transforming identifiable tokens into semantically rich representations.
In case you are worried about the way we are mixing metaphors and mathematics, I will let you in on a secret.
Machine learning is an alchemy where we mix precise mathematical equations with intuitive metaphors poured over a large cauldron of data subjected to extreme computational power in the hope that it all turns into a potion of immortal knowledge.
If that statement makes you uncomfortable, you should stick to something more definite like stock market speculation.
It might be helpful, at this stage, to have an idea what these embeddings look like. If we send our original domain specification to OpenAI API, and ask for its embedding, we will get a long list of numbers.
Input Text:
A user has a name, email address, and a role.
The role can either be regular or admin.
Number of tokens: 22
First 10 numbers of the embedding:
[-0.0041143037, -0.01027253, -0.0048981383, -0.037174255, -0.03511049,
0.016774718, -0.0476783, -0.022079656, -0.015676688, -0.019962972]
Size of the embedding: 1536
We get a vector of size 1536. That is the dimensionality of OpenAI embeddings8. Please note that this is the combined embedding for the entire text that is formed from the individual embeddings of each token in it.
If we sent just one token, say "user", here is what it will look like:
Input Text: user
Number of tokens: 1
First 10 numbers of the embedding:
[-0.004338521, -0.015048797, -0.01383888, -0.018127285, -0.008569653,
0.010810506, -0.011619505, -0.01788387, -0.02983986, -0.013996384]
Size of the embedding: 1536
It has the same dimensions, but different values for the embedding. You can
see them in their full glory in Embedding section of the python notebook
![]() .
.
Looking at those numbers, we can only hope those tokens were really enriched. Because, all I can say, at this stage, is that I am poorer by $0.046.
It is very difficult to visualize such high dimensional data. But we can apply some dimensionality reduction techniques and visualize them in 2D or 3D spaces. Here is what we are going to do:
-
We use a sample dataset containing 200 text descriptions and a category definition of what the text is describing. These samples are taken from a curated dataset9. Here are some examples:
Text: " Oxmoor Center is a Louisville Kentucky shopping mall located at 7900 Shelbyville Road in eastern Louisville."
Category: "Building"
Text: " Sten Stjernqvist is a Swedish former footballer who played as a forward."
Category: "Athlete" -
The sample dataset has 14 categories.
-
We then setup a language model that was pretrained for sentence embedding, similar to GPT, but can fit our wallet (free) and compute (we can actually run it from a notebook on Google Colab)10.
-
We ask the model to generate embeddings for each text description from our sample. We get embedding vectors of size 384, about one third the size of OpenAI embedding.
-
We reduce the dimensionality to 3 and plot it. The first plot shows all 200 text descriptions in 14 categories and the second one shows data for just 5 categories.
Fig 2 is interactive, so feel free to explore it closely. The
companion python notebook
![]() has interactive 3D plots for both.
has interactive 3D plots for both.

Fig 1. Embeddings of 200 text descriptions belonging to 14 categories
Fig 2. Embeddings for 5 categories (Interactive Plot)
Even in 3 dimensions, generated using a tiny model*, without any additional fine-tuning from our side,we can see the embeddings forming clusters along the categories their descriptions belong to.
* The SentenceTransformer model we used above has less than 23M parameters, embedding dimension of 384, sequence length of 256 word pieces and was trained on just over 1 Billion training pairs. A tiny model by today's standards.
We can even compute their similarity scores in higher dimensions. We compute cosine similarity, the angle between two vectors in high dimensional space. Larger the score, the higher the similarity between the embedding vectors. We average this score by category and plot as shown below.

Fig 3. Similarity score between embeddings
The brighter colors along the diagonal indicate very high similarity
score between the texts in the same category. You can also see some interesting
higher similarity scores across categories - (Plat, Animal),
(Artist, Album, Film), (Artist, Athlete, OfficeHolder),
(Building, EducationalInstitution), (NaturalPlace, Plant, Village). You can
investigate them more closely in the companion python notebook
![]() .
.
It is even more impressive considering the language model we used was not trained on the sample data we used as input. Also, the model has not seen the category labels in our sample data as we only fed the text descriptions to generate embeddings. Still, it is able to conjure up a representation, the embedding, that captures the semantic similarity between the texts, somehow.
This is the magic of LLMs that is causing all the buzz!
As amazing as it might sound, it is important to note the following,
- The embedding does not know anything about the actual categories. If we have to use our embeddings for, say classification, we need to do some more work with them.
- We really have no clue what exactly has been learned by these embeddings. We don't know what any of these 384 numbers really represent. All we can say is that each dimension captures some aspect of the input. The simple world of x and y coordinates and readily interpretable structured representations of User and Role are gone.
And moreover, we have not yet discussed how the embeddings gain their insights. Before we dwell on that, let us take a brief moment to discuss what these embeddings are good for.
There are several use cases for embeddings, from classical machine learning use cases such as classification, regression and visualization to search, information retrieval and code search. Even though a general LLM can provide quality embeddings for a wide range of use cases, typically there are specialized models fine tuned for specific tasks. For example, OpenAI provides separate models for text similarity, text search and code search.
We can spend as many words as we like (and can afford) in each use case11. Broadly speaking, embeddings are going to have the highest impact on search, information retrieval and knowledge representation.
The impact in the area of search must be very clear from the browser wars unfolding right in front of our eyes12. It does not matter if we use a search box or a chat box to access information, the information systems of tomorrow must produce better results based on context and semantic similarity. If that in fact turns out to be the yardstick of excellence in search, not keywords and proprietary ranking algorithms, then it will not only impact the revenue model of big search engine companies, but the business model of every company that depends on those search engines. The search for new business models in this new world of search has just begun!
How does this impact information retrieval and why is that any of our business? Consider the exponential growth of data13, approximately 80% of which is unstructured. And then consider this. Coupled with the growth of embedded smart devices such as our wearables, smart home devices etc. alongside more traditional sources such as computers and mobile phones, by 2025, a person on the average is expected to have more than 3 data driven interactions per minute14. The task at hand is to turn trillions of bytes of data into billions of human experiences. We have to not only find the proverbial needle in the haystack, but stitch a dress that fits the customer and her occasion under a minute! Extraction, storage and retrieval of relevant information from this data deluge is well beyond manual and structured representation capabilities that we relied on so far. The main feature, and the promise, of this new breed of language models is their ability to convert large volumes of unstructured data into incomprehensible (to humans), yet extremely useful representations, the embeddings.
The search and retrieval, as it happens, are equally important to building more efficient and scalable language models. Incorporating the search and retrieval mechanisms into the existing architectures is an active area of research and shown to have positive impact on performance and scalability of language models 15.
These things mean that the vector search engines and vector databases will soon be part of our basic production infrastructure just as ElasticSearch and database management systems are today.
There are so many technical advances in each of these areas. It will be difficult for us to dig any deeper into them in this article. We have not even got to the most interesting part of LLMs yet, the learning. Let us discuss that next.
Corridors of learning and pretrain years
We are ready to send our tokens with their embedding vectors on their backs to school. What kind of education should we give them?
If they were our kids, we want to expose them to as much of our collected knowledge on various subjects - history, biology, mathematics and so on. We also want them to develop their language and communication skills. We may like them to develop an appreciation for finer things in life, like arts and literature. We may want to provide them with opportunities to participate in sports and athletics, to play together with others or to cheer them on from the sidelines, and to inculcate the spirit of sportsmanship to accept victories with humility and defeats without hostility16. But more importantly, we hope that they learn general problem solving and social skills that empower them to be active, productive and successful members in the complex and demanding real world once they are out of their schools.
If we want to do the same for our tokens, what kind of school and curriculum would serve such lofty goals?
The overwhelming success of LLMs were mostly driven by advances and innovations in three areas - the training data (educational materials), the deep neural network architecture (layout and design of the schools) and the training process and infrastructure (methods of teaching).
Pouring over your data
Availability, abundance, accuracy and quality of study materials strongly influence learning. It will be very limiting and even counter productive if we were to depend solely on a selected set of written and curated books that are pre-screened and even censored by school boards. A major limitation of early language models was that they needed large datasets of labelled examples for each language task17. This was undesirable for practical and technical reasons18. The key promise from GPT-2 paper was finding a "path towards building language processing systems from their naturally occurring demonstrations" that are capable of performing many language processing tasks without the need to manually create and label a training dataset for each task.
That is just the engineering speak for parental angst that your child while capable of recalling the capital of every country might be confounded by the neighborhood street signs on their own.
Being able to train language models on enormous corpus of unlabelled data in an unsupervised manner was a pivotal step in the evolution of LLMs.
It does not mean we can indiscriminately use any text that we can scrape off the internet. Selecting, preprocessing and managing such large volumes of data itself is a very demanding and delicate engineering endeavor. Just to give you a perspective, here is the training dataset detail of the most recent language model LLaMA from MetaAI:
| Dataset | Sampling Prop. | Disk size |
|---|---|---|
| CommonCrawl | 67.0% | 3.3TB |
| C4 | 15.0% | 783GB |
| Github | 4.5% | 328GB |
| Wikipedia | 4.5% | 83GB |
| Books | 4.5% | 85GB |
| ArXiv | 2.5% | 92GB |
| StackExchange | 2.0% | 78GB |
Table 1. Pretraining data for LLaMA reproduced from the paper from Meta AI
The associated paper can also give you better appreciation for the process of setting up the datasets and turning them into 1.4 trillion tokens. Even when using only publicly available data, this process is complex, involved and costly.
The oversized and overexcited young language models can just as easily absorb the toxic and offensive19 along with all the good and act out in public that can embarrass their parent organizations20. The large language models have shown to reproduce and amplify biases that are in the training data and to generate inappropriate content. There are several benchmarks that can be used to asses the bias and toxicity of the models. These metrics are still evolving and there are no foolproof ways to absolutely safeguard against these issues.
Even when we might be using pretrained LLMs, it is important to understand the types of data that they were trained on, their known biases and toxicity impacts and the published benchmarks. It is important to acquiesce the unpredictability associated with these systems in real world settings, especially when it involves live interactions with humans.
It is your business and brand that gets tagged when such unpredictability shows up at the most unexpected and inappropriate places.
Learning by paying attention
When it comes to the architectural advancements that propelled the size and performance of LLMs into stratosphere, there is one paper, Attention is all you need, published by Google researchers in 2017 and the neural network architecture they proposed, Transformer, that was, without question, the most influential. It is almost impossible to miss them if you even have a fleeting contact with any informational material associated with LLMs. The ideas from this paper have been applied, refined, and adopted to every domain, still the core concepts from the original paper have retained their form, relevance and reverence21.
Our goal here is to create an environment to learn meaningful representations and problem solving skills from the mountains of text data that we prepared. Let us develop some intuitions about this process and ease into LLM specific details.
At the most basic level, all ML systems learn like children learning by solving problem sets. They are asked to solve problems, teachers score their performance on the problem set and give them feedback on how to adjust their solution steps to improve the score, and repeat22. For this process to work, we need
- The problem sets and learning objectives
- Representations of learnings that can be adjusted based on feedback
- A scoring mechanism to score the performance on problem solving tasks
- A mechanism to propagate the score back to the students and adjust their learnings appropriately
The preparation of problem sets for each subject is a daunting task. As we discussed in the previous section, our approach here is to expose them to large volumes of existing data, akin to creating a long reading list for students.
If we are presenting our students with a truckload of reading materials, obviously we expect them to read them. But beyond that, what kind of learning objectives can we set, especially if we are not building specialized problems sets. If we are interested in testing their language skills, how about asking them to fill in the blanks, as in "humpty dumpty sat on a _____" or "the _____ brown fox _____ over the _____ dog". Or, we can simply ask them to guess the next word in a sentence, as in,
humpty _____
humpty dumpty _____
humpty dumpty sat _____
humpty dumpty sat on _____
...
Those are the objectives used by prominent LLMs of today23.
Effectively we are converting this learning program into a sequence prediction or time series forecasting problem, very similar to how we shape our future executives by sharpening their quarterly forecasting skills. The idea here is to train the language model to predict the next word with high accuracy when prompted with a sequence of words as context. To do this, the system will have to learn the patterns and distributions of words in the language. Just like we all learned to add a 'u' after 'q' for no apparent reason.
What will they learn? This is where the deep neural networks and their parameter counts come into play. For theoretical, historical and pedagogical reasons, the most popular depiction of these networks involve layers of interconnected artificial neurons.

Fig 4. Fully connected deep neural network
Let us take a less romanticized view24. Remember, we represented our tokens using embedding vectors in a high dimensional space. What we want these layers to do is to transform input tokens into output tokens or vectors in one high dimensional space into vectors in another high dimensional space. It is similar to transformations such as moving a rectangle (translation) or scaling a circle in 2D. We apply an appropriate affine transformations, which is to multiply the input vector with an appropriate matrix, let us call it a weight matrix, and add a bias vector to it.
\[ y = f(x) = Wx + b \]
Here x (input), y (output) and b (bias) are vectors, W is a matrix (weights). We can think of each layer in a neural network as computing some function of the above form. When we put multiple layers together, we are just composing these functions, layer 1 computing function \( f_1(x) \), layer 2 computing function \( f_2(f_1(x)) \) by taking the output of \( f_1 \) as input and so on. We can build pretty complex functions this way. Just one problem though. When we compose linear functions, we get another linear function. But the world we live in is inconveniently nonlinear. Let us introduce some nonlinearity into the above function, something like,
\[ f(x) = \sigma(Wx + b) \]
Here \( \sigma \) is some nonlinear function, called an activation function. There are so many popular choices, such as sigmoid, tanh, ReLU etc. for this. While their primary role is to introduce nonlinearity, they serve many purposes least of which is to produce conveniently interpretable outputs for a task at hand. For example, a sigmoid activation function will output values between 0 and 1. We can normalize the output values (add all y values and divide each y value by the sum) and use them as probabilities. Another perfect example of mixing equations with intuitive interpretations!
Just one more thing. In ML systems, we deal with more than vectors and matrices. If you think of vector as an array of numbers and matrix as a table of numbers, a tensor is generalization of these arrangements into higher dimensions, a multi-dimensional array so to say. A scalar value is a rank 0 tensor, a vector is a rank 1 tensor, a matrix is a rank 2 tensor and so on.
The takeaway here is that a neural network layer is a set of tensor operations applied to its inputs. The weights and biases, the numbers we store in those tensors, are the parameters of the layer. These are the parameters what machine learning systems learn from the data. By doing so, they are learning to approximate functions that can transform inputs into outputs. We combine multiple layers to build deep networks, where by increasing the number of parameters in the network and complexity of functions it can learn. A network model or network architecture refers to specific arrangement of the layers and connections between them. We have come up with so many different kinds of specialized layers and their arrangements to solve different kinds of problems. The transformer architecture and the attention mechanism it refers to are additions to this ever-growing repertoire. This approach yields complex looking architectural diagrams like the one below.
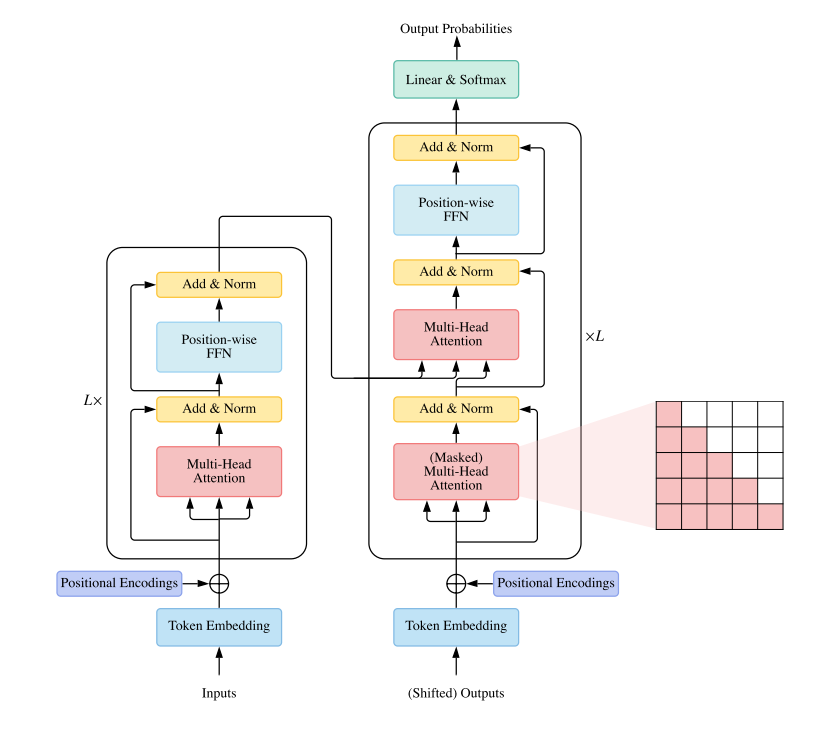
Fig 5. Transformer architecture diagram
It is application of linear algebra all the way. The tensor operations can be efficiently computed on Graphics Processing Units (GPU) and specialized Tensor Processing Units (TPU). The vital importance of fast and efficient computations in deep learning can't be overstated25.
Now that we have the parameters and necessary computations in place, how will the system learn the right parameters? We need some way to score the output of the network against the expected output. Such scoring functions are called loss or cost functions. Over the years, we have come up with many different loss functions that suite different learning tasks26. Take a simple case of fitting a line based on a list of \( x \) and \( y \) coordinate values. We let the model come up with an equation of the line, an approximate function representing the line by estimating parameters (the slope \( w \) and y-intercept \( b \) in this case). We can now compute the predicted \( y \) value, \( y_{pred} \), for each \( x \) value and compare it against actual value, \( y_{act} \). The errors in the model can be calculated by using mean absolute error \( \frac {\sum_1^N \left\lvert y_{pred} - y_{act}\right\rvert} N \) or mean squared error \( \frac {\sum_1^N ( y_{pred} - y_{act})^2} N \).
We need a similar mechanism for the word prediction task of LLMs. The difference is that we are dealing with probabilities and the loss function typically used is called cross entropy loss. Such loss functions can tell the network how far off its estimated probability distributions are from the actual distributions seen in the data.
The network has to adjust its parameters to reduce this loss. If it was linear algebra and probabilities so far, it is calculus time now. We will use the gradient of the loss function with respect to parameters as a measure of the influence of the parameters on loss.
It is like learning to throw the ball at a target. If the ball goes past the target, we want to reduce the force with which we throw and if it falls short, we increase the force. If the ball goes far behind, we lower the angle of throw and increase it it did not go far enough. Here we are adjusting two parameters, force and angle of throw.
The same principles apply. If the influence of a parameter on loss is positive, we want to reduce the parameter value by a small amount proportional to its influence. We want to increase it if the influence is negative. The gradients give us a quantity to adjust the parameters. The partial derivatives for tensor operations are automatically computed by the deep learning libraries like PyTorch using backpropagation algorithm. The optimization of model parameters in the network is accomplished by using one of many optimizers like Stochastic Gradient Descent (SGD).
The computations all the way up to the calculation of loss for a given input is called a forward pass and the recomputation of gradients and parameter updates is known as the backward pass.
It may all sound way more complicated than it really is. I have setup a
very simple network and trained it on a simple task to generate the next
character based on previous characters it has seen. It is built using basic
linear algebra and calculus we discussed above and trained on some text
from the works of Shakespeare. You can see it in the Learning Basics
section of the companion notebook
![]() .
It should help you develop better intuitions about this whole process, even
without understanding any of the code in the notebook.
.
It should help you develop better intuitions about this whole process, even
without understanding any of the code in the notebook.
One of the key challenges of language modeling is that it is context dependent. J. R. Firth famously said, "You shall know a word by the company it keeps". You really need to understand the context to understand the meaning. The networks we discussed above are feedforward networks, meaning the input moves only in one direction and there are no cycles. They have no memory or state awareness of input data. Recurrent Neural Networks (RNN) were introduced to address this problem. There are very effective and still popular today. But they suffer from limited memory, making it difficult to capture long term dependencies in data. They are also difficult to train as they suffer from vanishing or exploding gradients. Keeping the gradients in order is a problem in deep neural networks in general and far more so in the case of RNNs. Most importantly, the computations at each step in an RNN depends on the result of computation from the previous step, a major impediment to parallelization that limits scalability.
The transformer architecture directly addresses these challenges. Fig. 5 above shows the transformer architecture27. For a detailed understanding of the architecture, please refer to many excellent resources available online28 or read the original paper. We will only develop a high level understanding of key features of this architecture here.
As the title of the book, Everything is obvious, clarifies, once you know the answer, the fundamental ideas of this architecture may appear commonsense29. We already learnt about tokens and their embedding vector representations. This representation shall reflect the meaning of the token which depends on various contexts in which it appears. A context is defined by other tokens in the sequence they appear with. So, we take a sequence of embedding vectors of tokens in our input text, pass it to a mechanism, called attention, where we compute the influence of tokens on one another.
Let us consider the sentence "i went to the store". Assuming each word as a token for simplicity, the the input is a sequence of vectors \( [ v_i, v_{went}, v_{to}, v_{the}, v_{store} ] \). Each output vector in the sequence \( [ y_i, y_{went}, y_{to}, y_{the}, y_{store} ] \) are computed by taking a weighted average of the other vectors in the sequence. For e.g., if we take the token "went", the output vector \( y_{went} \) is computed as:
\[ y_{went} = \sum_{t=i}^{store} w_{went, t} v_t \]
where \( w_{went, t} \) is the weight of \( v_t \) and \( v_t \)
represents each of the 5 vectors of the input tokens. What should the weight
be? Each weight should reflect how far or close together the vectors are in the
space of their meanings. The way to compute such distances is the dot product
of the vectors. That means, the weights \( w_{went, t} \) are computed
as follows:
\[ w_{went, i} = v_{went} \cdot v_i, w_{went, went} = v_{went} \cdot v_{went}, w_{went, to} = v_{went} \cdot v_{to}, w_{went, the} = v_{went} \cdot v_{the}, w_{went, store} = v_{went} \cdot v_{store} \]
Kind of speed dating arrangement, if you are familiar with that idea. The \( y_{went} \) computation is now,
\[ y_{went} = \sum_{t=i}^{store} (v_{went} \cdot v_{t}) v_t \]
You do this for each \( v_t \) in the sequence to get \( y_t \). If the meaning of the token "went" depends more on the token "i" and less on "the", the network can learn to adjust the weights accordingly. It can learn to pay more attention to the token "i" and less to "the" by adjusting the weights and incorporate that in the output vector \( y_{went} \) for token "went".
The best part about these calculations is that we can arrange them neatly into tensors and compute them fast on a GPU or TPU. The basic self-attention, is just a couple of matrix multiplications. The practical attention mechanism as described in the paper and used in LLMs is a little more complicated.
It has the concept of query, key and value vectors, corresponding to the roles a given vector plays in the above computations. For e.g., we use \( v_{went} \) in 3 different ways,
- To compute the weight for its own output vector \( y_{went} \) on the
left side of the
dotproduct (query) - It is used to compute the weights of other tokens' output vectors on the
right side of the
dotproduct (key) - Finally, it is used as part of the calculation of weighted sum, \( v_t \) inside \( \sum \) above (value)
The names are reminiscent of retrieval from a key value store. Each of these vectors are given additional tunable weights. There are different types of attention based on the source of queries and key/value pairs - Self Attention, Masked Attention and Cross Attention. There is a lot more to attention mechanisms. Please do refer online resources28 or read the original paper for additional details.
There are so many different contexts and a given token can have different relationships to different neighbors even in a single context. In order to capture the richness and diversity of relations between tokens, transformers combine multiple self-attention blocks known as attention heads, giving rise to multi-head attention.
There are excellent visualizations of attention mechanism available online. The diagram below is taken from Deconstructing BERT: Distilling 6 Patterns from 100 Million Parameters showing a simple demonstration of different levels of attention tokens pay to others in a sequence.
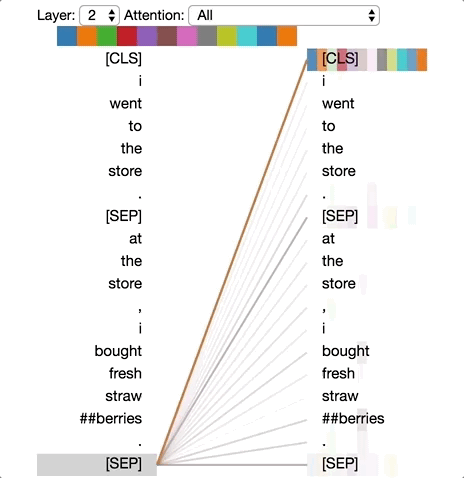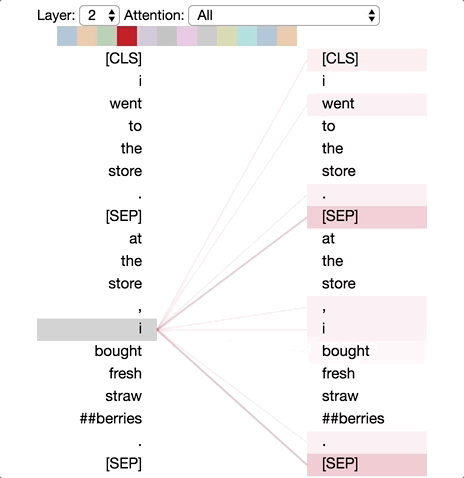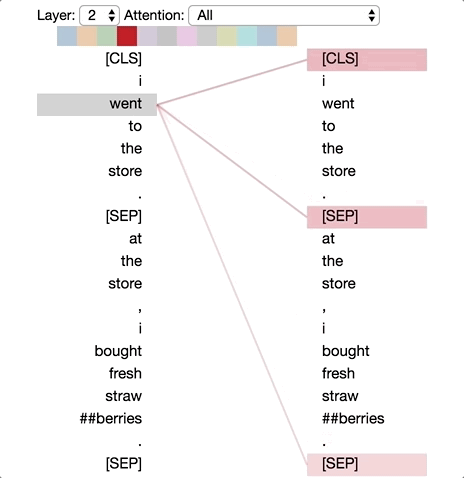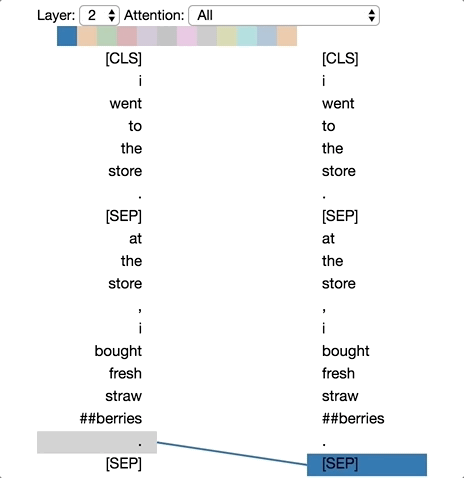
One important thing to note here. When we are mixing the vectors during attention as discussed above, the information about their positions in the sequence is missing from calculations. Instead of introducing state dependencies, the transformer architecture adds this information to the input vector using some coding scheme. There are different positional encoding schemes that are in use today, but we will not go into the details here. Keeping attention a set operation on the input vectors than treating them as sequence and adding in the sequence information using positional encoding is key to the scalability of transformer architecture.
The transformer is an architecture and attention is just one part of it. The true marvel of transformer architecture and the paper is not the originality of the ideas, but the shear beauty of application of many ideas together that drove human quest for artificial intelligence to new heights. Today, it is better to think of transformer as a family of architectures, rather than a single one. There are so many proposed variants, X-formers, where you can substitute a random word for X and there is a fair chance of finding a variant with that name.
There are 3 types of architectures used in LLMs today. Encoder-Decoder, as proposed in the paper, used in sequence-to-sequence modeling (e.g., machine translation). Encoder-only architecture, usually used for classification or sequence labelling problems. BERT is an Encoder-only language model. Decoder-only architecture, used for generative tasks and is used by GPT family of models.
The diagram below is a taxonomy of transformers taken from A survey of transformers by Lin et al. that should give you a sense of expanse of transformer universe.
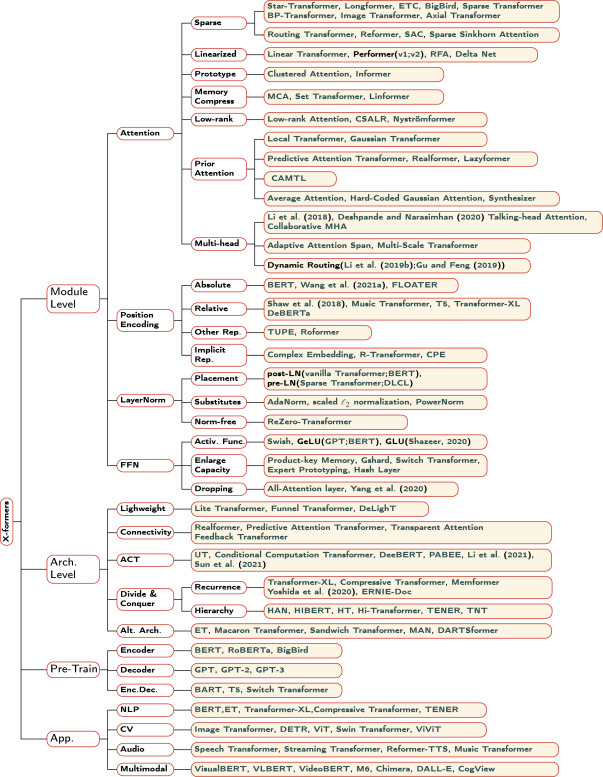
Fig 7. A taxonomy of transformers and representative models
We would hope that plenty of learning materials (datasets), a healthy appetite for learning (large network with lots of parameters), a strong motivation (improving predicted probabilities) and a nurturing environment (attention) is all we needed for a great education. Not quite!
It takes a village and a trust fund
Training these large models on monstrous datasets is arduous, intricate, laborious and exorbitantly expensive. This process is called pretraining. That is pretty much what most of us need to know about this process.
Here is some information that will help you appreciate the scale of pretraining.
- BERT model that has 340 million parameters was trained on a dataset of 3.3 billion words of text for 4 days using a cluster of 64 TPUs. It required an estimated 3.3 x 10^15 floating-point operations (FLOPs) and consumed approximately 300 kWh of electricity. The cost of training was in the range of tens of thousands of dollars.
- The largest version of GPT-2 which has 1.5B parameters was trained on a dataset of 40GB size over several weeks using a cluster of 256 GPUs. It required an estimated 3.3 x 10^17 FLOPs and consumed approximately 1.25 MWh of electricity. The cost of training is estimated to be in the range of several hundreds of thousands of dollars.
- The GPT-3 model that has 175B parameters was trained on a dataset of 570GB size for 14.8 days using over 10,000 GPUs. It required an estimated 3.14 x 10^23 FLOPs and consumed approximately 2.6 GWh of electricity. The estimated cost of training is several millions of dollars.
But these costs are coming down. According to some reports, with the help of new tools and platforms that are available today, the cost of training a language model to GPT-3 level costs less than $500K and the training costs are dropping ~70% per year.
Let me give you even more encouraging development in this front. Researchers at Stanford University have just introduced Alpaca, a 7B parameter model that is qualitatively similar to GPT-3 that can be reproduced for less than $60030. They used GPT-3 to build instruction data to fine-tune a smaller 7B parameter LLM model LLaMA which then performs on par with the larger model. The methodology is really promising, even though their choice of LLMs raised licensing hurdles with both OpenAI and MetaAI.
It is too early to predict how it all will play out, personal LLMs perhaps? Really?
Ask not what you learned, ask what you can do
The question, at this stage, is what do LLMs learn from their costly ivy league education. Frankly, we really don't know. It is far more easier to answer what kind of jobs they demonstrably excel at. And to most of us, that is what matters.
What kind of skills can these pretrained LLMs pick up after burning the midnight oil (and parent's money) pouring over data trying to predict the next word? Far more than anyone ever expected. The original paper that introduced GPT-3, titled Language Models are Few-Shot Learners, was one of the first ones to notice that these very large models, GPT-3 was the largest at the time, have developed broad set of skills and pattern recognition abilities that they are able to use to rapidly adapt to carry out new tasks, a phenomena they referred to as in-context learning. In other words, they have necessary skills to learn new tasks with zero or a few task specific examples. The process of learning from zero or a few demonstrations is called zero-shot or few-shot learning respectively. They also found that these kinds of learning improve dramatically with the size of the model. Most importantly, the in-context learning required no additional tuning of parameters of the pretrained model, required very few demonstrations and these examples could be given as plain text. This changed everything and uncovered a world of possibilities for use of LLMs by new breed of training methods, which we will cover in the next section.
The impressive gamut of capabilities demonstrated by GPT-3, including its ability to reason on-the-fly, compose prose and poetry, and perform many other language tasks, caught the attention of the media and captured the imagination of the public with two consequences. It opened the floodgates of really large language models and OpenAI concluded that the open part of their name was just a decorative flourish31.
How exactly does the in-context learning work? Well, it is an active area of research32 and the exact mechanism at work remain unclear.
Recent studies show early evidence that many capabilities demonstrated by large models are emergent abilities at large scale, meaning these abilities were not present at smaller models but present in larger ones. The performance of LLMs on several tasks dramatically improves after certain scale thresholds, a phenomenon known as phase transition. Please note that the scale is not just a function of number of parameters in the model, but also that of amount of training compute and the size of training dataset.
It appears that the virtuous circle of a highly scalable architecture with billions of parameters that can be trained over massively large datasets using highly distributed training infrastructure seems to unleash the genie from the bottle at some point.
Talking about emergent abilities, there is evidence for emergence of theory of mind in LLMs. Theory of mind is our ability to impute mental states to others, their knowledge, intentions, emotions, believes and desires. The "I know that you think that her feeling about his attitude..." kind of things we do with ease that is central to our social interactions, communication, empathy and self-consciousness. Now, that is mind-blowing!
The specific objectives used during pretraining also impacts the performance of LLMs on specific skills. Models like GPT-3 that uses decoder-only architecture and trained to predict next word show remarkable text generation and prompt-based learning capabilities while models like T5 trained to recover masked words perform well on supervised fine-tuning, but struggle with few-shot in-context learning.
What kind of LLM do we need? It depends, on many factors - from the tasks we want to perform, to amount of data and training budgets we have, to volume of transactions and volume of text we want to use both as context and question, to our business models and licensing requirements and more.
Can a pretrained LLM do any job? As the paper ChatGPT: Jack of all trades, master of none points out, "a bigger model does not mean better at all in terms of following the human expectations of the model".
Getting a pretrained LLM ready for real jobs that meet our expectations is the next big step.
On the job training
To understand the nature of job specific training of LLM, it will be instructive to understand the process of turning a language model like GPT-3 into a chat application like ChatGPT. To make GPT-3, pretrained on large publicly available data, safer and better aligned to user expectations, OpenAI created InstructGPT, which used a technique called Reinforcement Learning from Human Feedback (RLHF). This used actual human feedback to update model parameters. The latest iteration of such models fine-tuned by InstructGPT is ChatGPT. The base model in ChatGPT has only 3.5B parameters, yet it performs better in conversational tasks than the 175B GPT-3 model.
The approach used by Stanford researchers when creating Alpaca model that we saw earlier is a more refined and automated variation of the above technique.
In general, the approaches to job training for LLMs fall into three categories - Fine-tuning, Prompt learning and In-context learning.
Fine-tuning
This involves retraining the model on a specific task or domain using smaller task or domain specific data. Fine-tuning typically requires more data compared to the other two approaches and involves changing the model parameters. But it can deliver state of the art performance. In addition to domain and task specific tuning, they are also used for multi-task and multi-modal fine-tuning. The pre-trained weights of the model are typically kept fixed, and only the weights associated with the task-specific layer(s) are updated.
Prompt learning
In this approach, rather than changing the LLMs to adapt to new tasks, we reformulate the tasks as textual prompts that look similar to the ones LLMs seen during their training. An example of this would be a completion prompt as shown below.
The prompt:
I missed my lunch today. I feel very
Output:
hungry
Here is another example of a prompt asking LLM to do sentiment classification:
Decide whether a Tweet's sentiment is positive, neutral, or negative.
Tweet: I loved the new Batman movie!
Sentiment:
The idea that we can use an LLM to do our work just by pausing the right question or prompt is very enticing and exiting. But to get the best results, we have to find the best or the most appropriate prompts. This has introduced a brand new field, prompt engineering. Is it time to rename your "search keyword optimization" team to "prompt engineering" team?
In-context learning
The key idea here is to leverage the emergent few-shot learning capability of LLMs to teach them new tasks by using a few examples or demonstrations. These examples can be written in natural language form. A query and the demonstration context together form a prompt that can be submitted to the large language model. In some sense, in-context learning is a subclass of prompt learning where demonstrations are part of the prompt. The language model will learn to provide better answers to the queries by using the demonstrations. There are no parameter updates or changes to the model.
This paradigm is very attractive for several reasons. It provides easy to use and interpretable interface to communicate with LLMs. It is also easy to incorporate domain knowledge. Since there are no parameter tuning involved, they make it easy to offer LLMs as a service to customers.
These approaches and their many variants are the most consequential part of LLMs that impacts all of us, especially anyone building and using digital systems. This is an entirely new way of capturing domain knowledge, a new way to specify our requirements, a new way to solve problems using a digital system, a new way to learn, a new way to teach, a new way to serve and search. It changes everything!
We will explore the systems engineering and problem solving with LLMs in detail in the next article.
Swimming in the ocean
This is probably a much longer article than I had anticipated. Still we have only scratched the surface.
The applications of LLMs to real world use cases is an important and deeper topic that demands its own dedicated and detailed exploration.
We also mentioned the knowledge representation area only in passing. Another important subject is multi-modal systems, as evidenced by just released GPT-4. We were not able to accommodate these topics in this article.
In an attempt to clarity concepts, we appealed to their simplicity. That does not mean they are ordinary or obvious. The simplicity of concepts comes from the distillation of knowledge and availability of tools, as a result of years of innovation, hard work and dedication of researchers and engineers in this field. If any of us can see this world more clearly, it is because we are standing on their shoulders.
It will also be a remiss not to mention those who persevered and persisted, guided by the courage of their convictions, to push the neural network research forward, even when they fell out of fashion. People like Geoffrey Hinton, Yoshua Bengio and Yann LeCun. They are the true heroes of this revolution.
Why, I wonder?
Technology is not a solution to all our problems. As a technical person, I would paraphrase, "Technology alone can't solve our problems without the ingenuity and intuitions to apply them to our problems". Without the applications, they are just paperweights. The application of technology requires a deep understanding of the domain, strong appreciation of the problems and the nature of solutions, and awareness of the potential of technology. This requires participation of practitioners, purveyors and potential beneficiaries of technology from all walks of life.
So does the future of LLMs and their transformative potential in our daily lives.
If you are one of those who believe that this is yet another fad that will fade, then all of this is none of your business!
Request for feedback
I like to hear from you.
Please share your comments, questions, and suggestions for improvement with me!
People actually tried to fit an elephant. The best approximation using four complex parameters was found in 2010. You can see a demonstration of fitting an elephant on Wolfram site.
Richard Sutton is considered one of the founders of modern reinforcement learning. Anyone who is familiar with this field should have come across his seminal book Reinforcement Learning: An Introduction.
All code snippets are either in Rust or Python. You can follow the article without actually understanding or running any code. Most of the code examples are very simple and any unnecessary details have been hidden away as much as possible. In the Python notebooks, follow the text guidelines.
I am not stereotyping LLMs here. There are so many of them, each one unique and beautiful in its own way. I am just trying to explain the general principles at work without getting lost in the details.
I am trying to reduce the cognitive overload that comes with so many acronyms and deliberately avoiding additional details in the main text. Tokenizers typically just don't blindly convert each word into a token. GPT-3 uses Byte-Pair Encoding (BPE) tokenizer which is a subword tokenizer. If you are interested in learning more about tokenizers or using them, you can refer to tokenizer section in the Hugging Face documentation.
The vision transformer (ViT) uses a patch-based tokenization scheme that converts the input image into a sequence of 16x16 flattened image patches. Feel free to refer to the original paper or a million other articles and videos about it on internet.
OpenAI uses three different encoding schemes across its various models. See the following cookbook for more details.
The samples are taken from DBPedia validation dataset. This is the same sample file used in the embedding blog by OpenAI
We use Sentence Transformers that can generate sentence, text and image embeddings. We chose a smaller pretrained model, all-MiniLM-L6-v2. There are differences between this model and GPT, but they both belong to Transformer family of language models. There is a similar interactive plot of embeddings in the embedding blog by OpenAI where you will see much better clustering effect. We can get similar effects by using better pretrained models ourselves. Here we just need a toy example to develop our intuition. It does not necessarily mean that the GPT embeddings are superior. In fact there is an interesting article on the subject that you can read in case you are interested.
If you want to know more about any of the use cases or understand how they fit your specific needs, please reach out to me.
For a high level appreciation of the impact of the language models on search, you can refer to this 2019 article from Google.
According to some estimates, the size of globally created and consumed data is expected to reach a whopping 180 zettabytes by 2025 (that is 180trillion gigabytes).
WebGPT which incorporated a text based browser to fine-tune GPT-3 to answer open-ended questions more accurately and RETRO - Retrieval Enhanced Transformer from DeepMind which uses a 2 trillion token database to deliver performance comparable to GPT-3 using 25x fewer parameters are examples of this.
We probably should keep them away from broadcasts showing after game fan celebrations of adults.
Language processing tasks refer to a wide range of Natural Language Processing (NLP) tasks such as sentiment analysis, text classification, named entity recognition, language translation, text summarization, question answering, text generation and so on.
The GPT-2 paper and the paper "Language models are few-shot learners" that introduced GPT-3 discuss many training (specifically pretraining) considerations with respect to datasets.
We are all the same liberals at heart except for the things that uniquely offend us.
There are many widely reported instances of AI systems misbehaving, two from Microsoft alone. An old story involving a chatbot named Tay in 2016 and the more recent one with chatbot in Bing.
There are more than half a dozen survey papers alone on Transformer architecture just since 2021. Anyone pursuing a technical career in ML field must read the original paper and at least one of the review papers.
It is a gross injustice to reduce 75 years of research and development in this field to a sentence. I am trying to develop the minimum intuition necessary to understand the language models.
There are several objectives in use today. GPT-3 uses so called Causal Lanugage modeling objective which involves guessing the next word based on the words it has already seen whereas models like BERT are based on an objective to recover subset of words masked out of input. There are recent proposals to leverage the strengths of both these schemes.
I am not attempting teach neural networks or deep learning here. I am using the bare minimum of information necessary to develop the intuitions for understanding the workings of LLMs. There are so many wonderful courses and introductory materials available for learning these topics. For starters, I highly recommend the Neural Networks and Deep Learning book by Michael Nielsen. There is also the deep learning book. If you want to get a visual understanding of neural network learning, I also recommend the tensorflow playground.
The hardware acceleration provided by GPUs is one of the main factors that contributed to early success of deep learning.
You can take a look at the loss functions in PyTorch library. This guide is good source for understanding loss functions better.
This architecture diagram is taken from the survey paper by Lin et al.
Please refer to The Illustrated Transformer blog post for more detailed understanding of the internals of transformer architecture. The Transformers from scratch by Peter Bloem is also an excellent resource, so are his video lectures on the same subject.
That is a statement of pure appreciation of the simplicity of ideas, conceptual elegance and the technical brilliance. It also does not mean that theory and technical details are simple.
They use GPT-3 to generate instruction-following dataset which they used to fine-tune LLaMA model from Meta. They were able to do this in 3 hours using 8 80GB GPUs. But the model has commercial use restrictions owing to specific licensing restrictions from OpenAI and Meta.
I have no issues with OpenAI pursuing commercial interests. I believe it is a noble cause as any and every company has the right to alter its course as they seem fit. OpenAI can (and even should) protect valuable intellectual property that it has created. But I do have issues when any private company profess to protect the public from the potency of technology that it is creating. First, it is counter intuitive and an argument for more openness and transparency. Second, it raises the question if public has the right to intervene and curb the development of such potentially harmful technology in the interest of public safety. I am sure not one who wants to be on the other side of that debate.
One of the papers explains in-context learning as implicit bayesian inference. There is also a recent survey article on the subject.
Copyright 2023 Weavers @ Eternal Loom. All rights reserved.